Flow mapping is the process of relating elementary flows in one dataset to similar flows in another dataset. In the context of the Federal LCA Commons, typically users are mapping the elementary flows in a third-party dataset (such as Ecoinvent or a dataset from the openLCA Nexus) to the Federal Elementary Flow List (FEDEFL).
Flow mapping is a critical step for accurate and complete LCIA flow characterization when using multiple LCI repositories in a single project database. In order for LCIA methods available on the FLCAC to fully capture the elementary flows present in a project database or product system they must be mapped to the FEDEFL as this flow list is the basis of LCIA methods on the commons.
Getting Started with Elementary Flow Mapping¶
On this ‘Getting Started’ page you will find guidance for accessing the FEDEFL, creating project mappings to convert your existing LCA project inventories to match the FEDEFL, and using our online interface to convert your new mapping files to a JSON-LD file for importing into openLCA.
Download for Use¶
The current FEDEFL release is available on the Federal LCA Commons here:
Simply click “Download” and select the format you prefer. JSON-LD is recommended for use with openLCA. Create a new database in openLCA, selecting ‘Units and flow properties’ under the ‘Database content’ category, then import your JSON_LD file to get started.
The TRACI LCIA method is also available on the Commons mapped and ready to use with the FEDEFL. It can be found here:
To learn more about the Federal LCA Commons click here:
Mapping a Dataset¶
This section provides guidance to users interested in generating a mapping of their own dataset or existing openLCA projects to the FEDEFL. This will enable integration with the current repositories on the Federal LCA Commons that were generated using the FEDEFL.
Resources for Mapping¶
Mapping Template: The mapping template file simply supplies the column headers required for you to generate a mapping file, which corresponds to the format specifications. As described below in the Preparing Source Data section you will want to start with a UTF-8 encoded CSV and paste these headings into the first row.
Complete list of FEDEFL flows: This file provides all of the flowables and associated contexts in the FEDEFL and corresponds to the flow list format. This list includes CAS numbers and some synonyms for the flowables which can be helpful when mapping. This file also indicates which flowables are ‘preferred’ as well as which alternate units and conversion factors are available for each flowable. For more details about the flow list, please see the EPA report.
All current mappings: This file provides all of the existing mappings housed within this repository and corresponds to the flow mapping format. This list includes the ‘SourceFlowName’ and ‘SourceFlowContext’ entries for various datasets and the corresponding ‘TargetFlowName’ and ‘TargetFlowContext’ which can be helpful when mapping. This file also indicates the ‘SourceUnit’, ‘TargetUnit’, and any ‘ConversionFactor’ that may have been used.
All contexts: This file provides all of the available environmental contexts for FEDEFL and corresponds to the flow mapping format. This list includes only the ‘TargetFlowContext’ names. This file is helpful when determining which contexts to assign for your flows.
openLCA to FEDEFL flow mapping file: GreenDelta and ERG developed a flow mapping file between the openLCA and FEDEFL flow lists. This file can be directly applied in openLCA using the openLCA flow mapping feature. Instructions on using a mapping file in openLCA can be found here.
Preparing Source Data¶
To start you will need a list of the elementary flows you wish to map. This may be newly collected data or an existing inventory you wish to convert to be FEDEFL compatible. Flows include the flowable names and their associated environmental context. The EPA report provides detailed definitions for elementary flows and the various flow components which are needed to model them appropriately.
If you already have an openLCA database that you would like to map, you can export the flows using the following python script in openLCA. Make sure to update the csv file name and path as appropriate. To use this script in openLCA, select “Tools” --> “Developer Tools” --> “Python”.
import csv
from org.openlca.core.model import FlowType
from org.openlca.core.database import FlowDao
from org.openlca.io import CategoryPath
# => define the path to the CSV file here. Use of forward slash required.
CSV_FILE = "C:/Users/ms/Desktop/flows.csv"
with open(CSV_FILE, "wb") as f:
writer = csv.writer(f)
writer.writerow(["FlowName", "FlowUUID", "FlowContext", "SourceUnit", "CAS", "Formula"])
dao = FlowDao(db)
for flow in dao.getAll():
if flow.flowType != FlowType.ELEMENTARY_FLOW:
continue
cat = CategoryPath.getFull(flow.category)
refq = flow.referenceFlowProperty
refu = refq.unitGroup.referenceUnit
try:
writer.writerow([flow.name, flow.refId, cat, refu.name, flow.casNumber, flow.formula])
except:
try:
writer.writerow([flow.name, flow.refId, cat, refu.name])
except:
writer.writerow(["[Flow encoding error]", flow.refId, cat, refu.name])You can specify the file path where you would like to save the output from openLCA.
It is good practice to check that all elementary flows have been exported correctly.
In the exported file, search Flow Name column for [Flow encoding error]. If identified, UUID can be used to identify the offending flow in your database and fix in the exported list.
To check that all flows were exported, compare the count of your exported flow list to results of the following SQL query:
SELECT COUNT(REF_ID) FROM tbl_flows. To use this query in openLCA, select “Tools” --> “Developer Tools” --> “SQL”.
The above python script will export all elementary flows from the database it is applied to. If applicable, it is recommended that the user remove all FEDEFL flows from the exported flow list to minimize the size of the mapping file. This will help avoid overwhelming Excel. The Index/Match formulas, described below, can be used to identify and remove FEDEFL flows.
Once you have the data for which you want to create a mapping, follow these steps:
Create a UTF-8 encoded CSV file using Excel or other appropriate software. To do this in Excel, open a new workbook, select “Save As”, and pick the “CSV UTF-8” file type option, using whatever file name you prefer. This encoding will help ensure that formatting and special characters are properly retained while you work with the file.
Utilizing the mapping template hosted on this GitHub repository, copy all of the column headings into the first row of your workbook. This is the standard layout for FEDEFL mapping files.
Paste in your ‘Source’ data using the appropriate fields. Your list being mapped is the ‘Source’, while the FEDEFL names are always the ‘Target’.
The flowables must conform to the definition provided in the EPA Report, which also details the criteria for preferred flowables.
Mapping Flowables¶
Download the FedElemFlowList
_1 .x .x _all .xlsx and All_Mappings.xlsx, which are described above in Resources for Mapping. You must then go through the process of identifying the appropriate FEDEFL ‘TargetFlowName’ entries which match the ‘SourceFlowName’ entries you added to your template in the pre-formatting steps. The FEDEFL and All_Mappings CSVs will ensure you are using mappings that have been developed and verified by FEDEFL maintainers.
If using Excel, we recommend using an Index/Match formula across the files to generate the appropriate mappings in your ‘TargetFlowName’ based on your ‘SourceFlowName’ column.
=INDEX('TargetFlowName' array in resource files,MATCH('SourceFlowName' entry in mapping template,'SourceFlowName'array in resource files,0))
Example formula in cell H2 for ‘TargetFlowName’ in the template:
=INDEX('All_Mappings.xlsx'!$H:$H,MATCH(B2,'All_Mappings.xlsx'!$B:$B,0))
This formula can be applied to the whole list to generate as many mappings as possible, simplifying the process. If you have CAS numbers in your source data you can put them in an additional column in the mapping template and do a match to the FEDEFL file using the CAS numbers.
In some cases you may not find a match using existing mappings. In these cases we recommend checking the following references to identify the CAS or any synonyms that may be associated with your ‘SourceFlowName’:
If you were able to identify a synonym or CAS you can check the FEDEFL CSV again to identify the appropriate ‘TargetFlowName’.
The ‘MatchCondition’ field does not impact the automated JSON generation, but can be helpful to record relationships between the ‘SourceFlowName’ and ‘TargetFlowName’. The Flow Mapping format guidance provides standard signs used for this field.
Mapping Contexts¶
Using your template and the resources you have downloaded you must now match the appropriate FEDEFL ‘TargetFlowContext’ entries to the ‘SourceFlowContext’ records you added to your template in the pre-formatting steps.
You will want to make a list of each unique ‘SourceFlowContext’ entry and create matches to the appropriate FEDEFL ‘TargetFlowContext’, referencing the All Contexts resource file.
Once you have your list you can add the mappings to the ‘TargetFlowContext’ column of your mapping file.
You will want to check contexts carefully if the ‘SourceFlowContext’ is unspecified or limited to the primary contexts (air, ground, water). In some cases ‘SourceFlowNames’ may contain information relevant to the mapping of the context, for example:
Gas, natural, in ground which would map to the ‘TargetFlowContext’ resource/air/subterranean
orWater, river which would map to the ‘TargetFlowContext’ resource/water/fresh water body/river
Mapping Target Units¶
You can use a similar Index/Match formula to generate the appropriate mappings for your ‘TargetUnit’ column based on your ‘SourceFlowName’ column.
=INDEX('TargetUnit' array in resource files,MATCH('TargetFlowName' entry in mapping template,'TargetFlowName'array in resource files,0))
Example formula in cell K2 for ‘TargetUnit’ in the template:
=INDEX('All_Mappings.xlsx'!$K:$K,MATCH(B2,'All_Mappings.xlsx'!$H:$H,0))
This formula can be applied to the whole list to generate as many mappings as possible, simplifying the process. You can also reference the full list of FEDEFL flows to verify the ‘TargetUnit’ or to identify any alternate units. If your ‘SourceUnit’ does not match the ‘TargetUnit’ but is listed as an alternate unit in the FEDEFL, a conversion value will automatically be applied to your mapping during the generation of the JSON file. If using the CSV-based mapping file, all conversion factors should be specified in the csv file.
If left blank, the ‘ConversionFactor’ field is assumed to be 1, meaning that the source flow and target flow are in the same units and quantity. Conversion factors must be formulated such that the flow value can be multiplied by the ‘SourceUnit’ to derive a flow value in the ‘TargetUnit’.
Remaining Fields in the Mapping File¶
The remaining fields are not required for your mapping file:
‘SourceList’: Can be used to record a name for your source data
‘SourceFlowUUID’: Can be used to record the UUID from your source data if applicable
‘Mapper’: Can be used to record the name of the person who mapped the flow
‘Verifier’: Can be used to record the name of the person verifying the flow mapping
‘LastUpdated’: Can be used to record the date that the mapping was generated
Flow Mapping: Details to Consider¶
Be cognizant of the presence of isomers if using chemical formula as a basis for flow mapping (i.e. one chemical formula can be associated with >1 flow names).
Not all contexts exist for all flows within the FEDEFL
Source water flows marked as
resource, in ground(or similar) cannot be mapped toresource/ground/subterraneancontext as only the more generalresource/groundcontext exists for Water in FEDEFL.Source Natural Gas flows marked as
resource, in ground(or similar) will map toresource/aircontexts in FEDEFL. Noresource/groundcontext exists within FEDEFL for Natural Gas.
Use of the suggested INDEX() match function will return the first identified instance of a viable mapping. The first match may not be the best match.
If using Excel’s index/match functions, be aware of matches that may be case sensitive (e.g. mg vs Mg) or matches that involve special characters (t*km), where * is a special character, as these can lead to undesired matches.
Using your Mapping File¶
The mapping file you just generated can be converted into csv or JSON-LD format and loaded into openLCA to map your database. The user’s comfort with Excel or python will determine which mapping format option is appropriate.
Generating a CSV-based Mapping File¶
For users who prefer to work in Excel, a csv-based mapping file can be generated using a semicolon delimited list. The linked Excel workbook provides detailed instructions on generating a mapping file that can be used in openLCA. To generate a csv-based mapping file you need to first map your source dataset to your target dataset using the instructions above, under the heading ‘Mapping a Dataset’.
This approach requires several additional lookups to populate data fields associated with:
SourceFlowUnitUUID’ and ‘TargetFlowUnitUUID’
‘SourceFlowPropertyName’ and ‘TargetFlowPropertyName’
‘SourceFlowPropertyUUID’ and ‘TargetFlowPropertyUUID’
Generating a JSON-LD File¶
Creating a JSON-LD mapping file requires the use of the fedelemflowlist Python package. Save your completed mapping as developed from the instructions above. This file needs to be saved as a csv and placed inside the “flowmapping” folder within the fedelemflowlist package. Next, open the “writemapping_to_use variable with the name of the mapping file. For example, for a file named “my_mapping.csv”, enter: mapping_to_use = [‘my_mapping’]
Running this script will generate a JSON-LD file saved to your local user data directory (see the console for the file path). This file can then be imported into openLCA when flow mapping.
Mapping a Dataset within openLCA¶
Instructions created for openLCA version 1.10.2 and verified in version 2.2.0
The Flow Mapping feature in openLCA allows users to map existing databases to standardized elementary flow lists (the FEDEFL) using either the csv or JSON-LD mapping file, described above.
The stepwise approach to complete this mapping is as follows:
Start with your openLCA database with complete openLCA reference data. It is recommended that users save a copy of their database before the mapping for reference.
Before starting the mapping process, you can select a sample process to view elementary flows specified before the mapping. Remember this process and come back to check it after the mapping process is is complete to ensure the mapping was completed correctly.
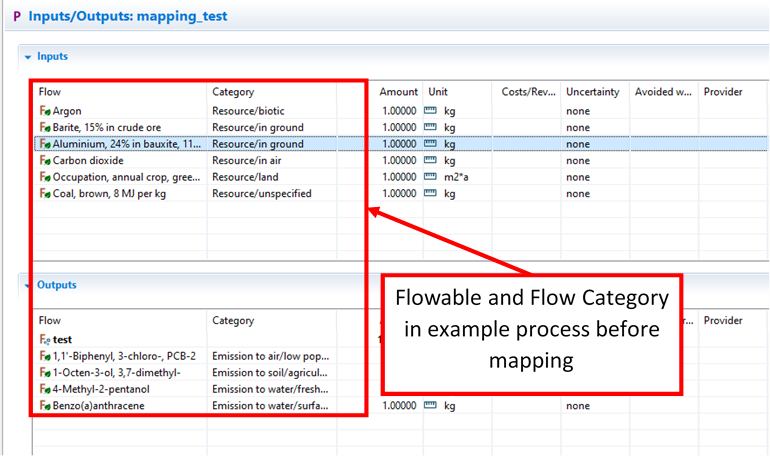 |
Have your csv or JSON-LD file with the mapped flows ready (instructions above). Select Tools, Flow Mapping (Experimental), Open file. Navigate to the mapping file location within Windows Explorer and select Open in Windows Explorer.
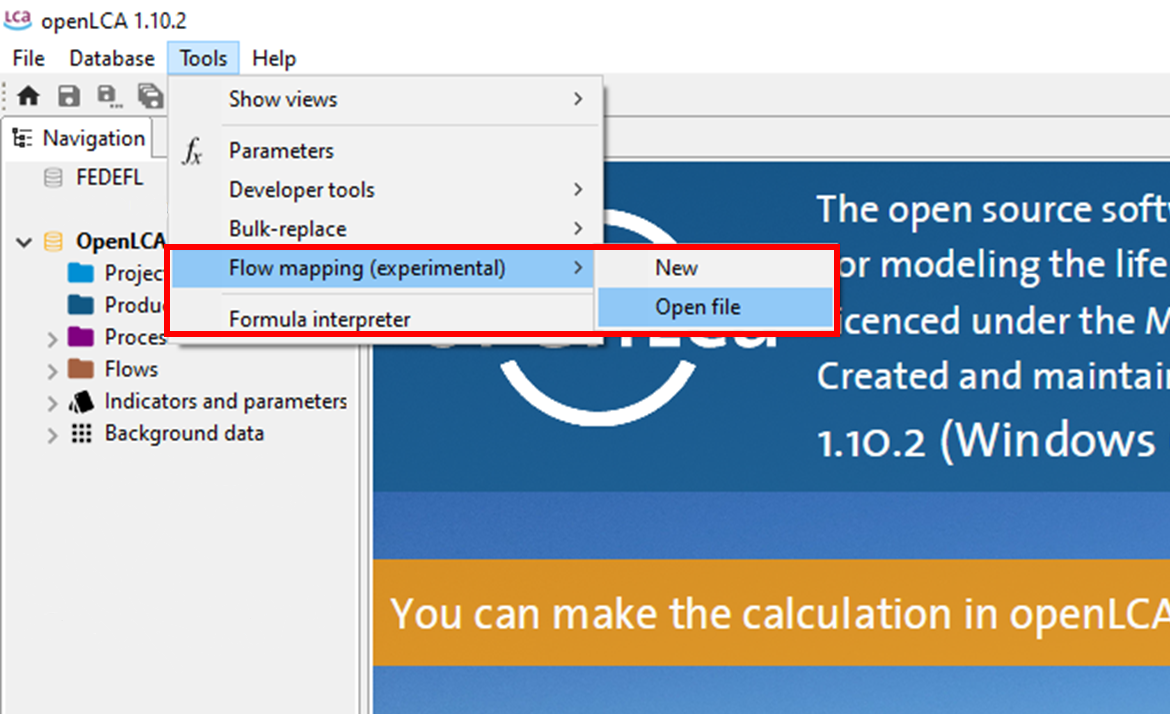 |
4a. If you are mapping with a JSON-LD file, select Open mapping definition. Open mapping definition should indicate the mapping file you have selected. Select Okay.
4b. If you are mapping with a csv file, the file will be recognized automatically when selected in the File Explorer.
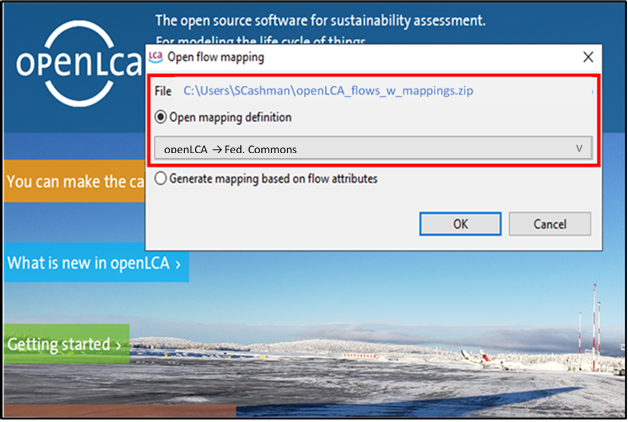 |
5a. If you are mapping with a JSON-LD file, the source system should be your existing openLCA database. You can select the source system by clicking the database icon. The target system should be your JSON-LD mapping file. You can select the target system by clicking on the paper icon.
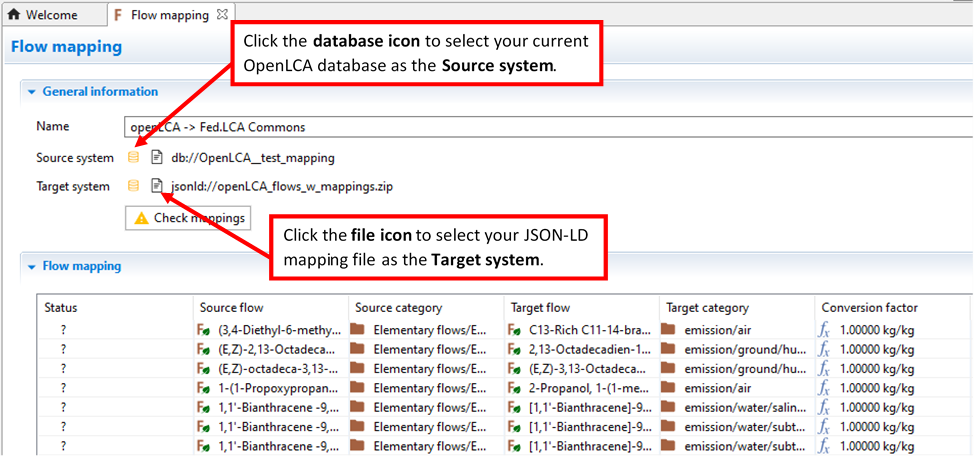 |
5b. If you are mapping with a csv file, the source amd target system should be your existing openLCA database. Both can be selected by clicking the database icon.
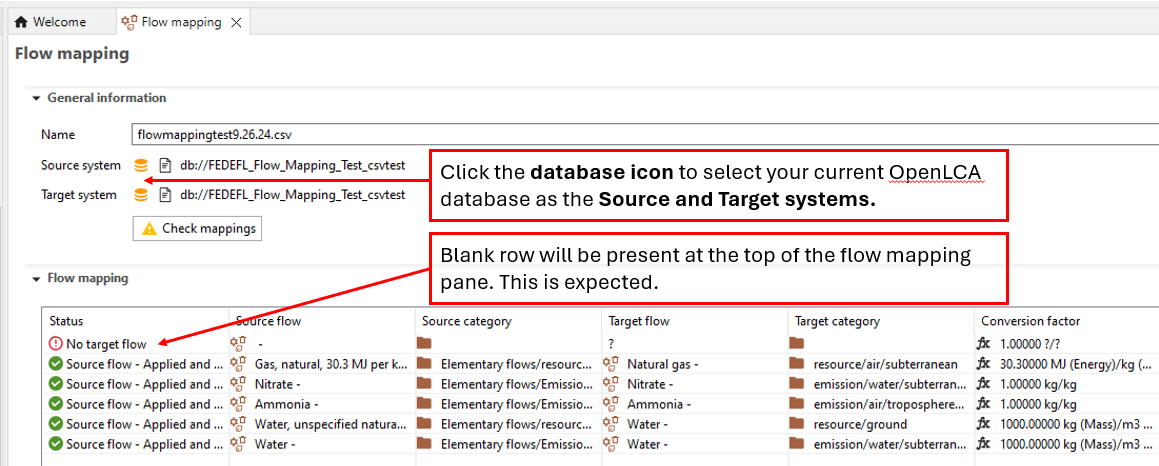
Click on the Check Mappings button to run a check on the mapping.
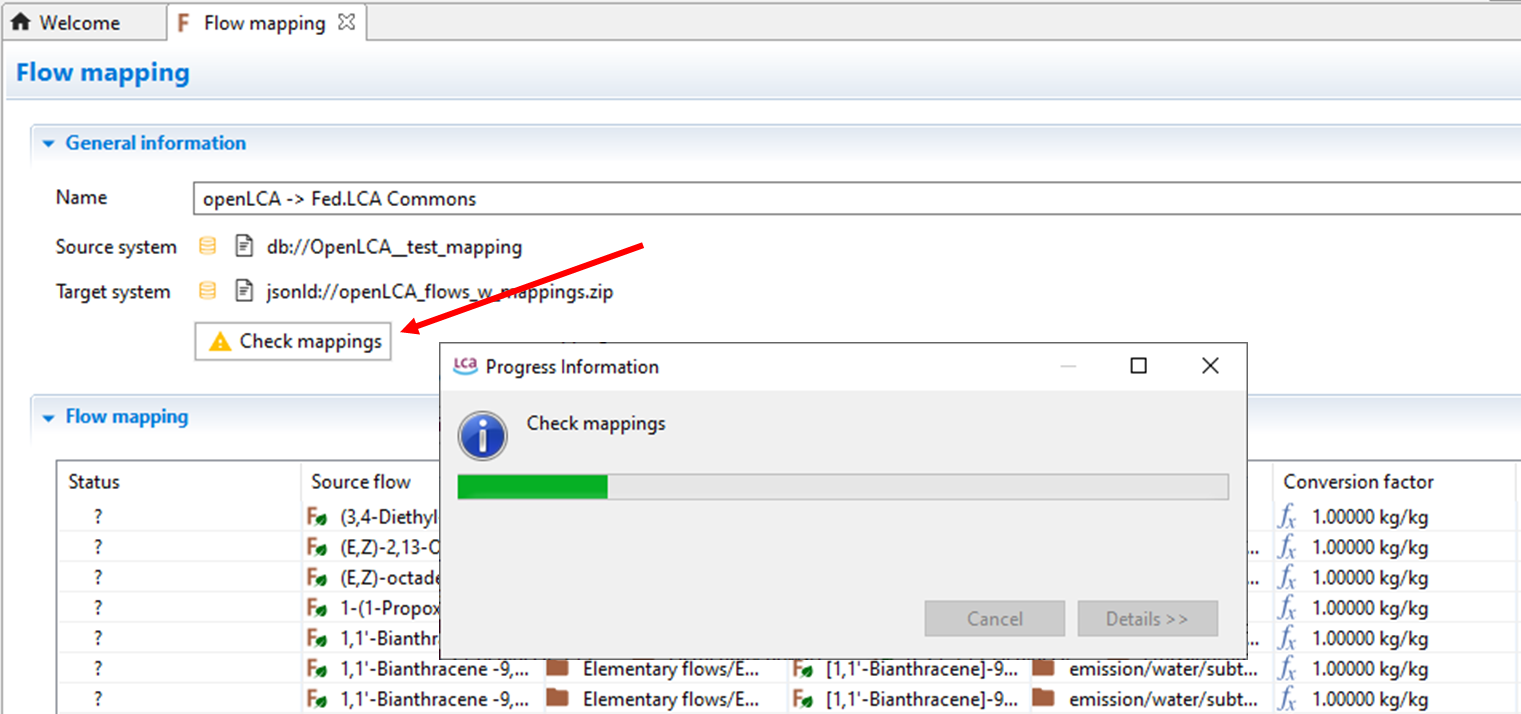 |
When the checking is complete, the mapping status will appear in the first column. A green checkmark will indicate if the flow is in sync with the database and there is a successful mapping. Error messages will show if there is an issue with the mapping. For example, error messages will show for missing target UUIDs if the mapping file did not contain the correct FEDEFL flows.
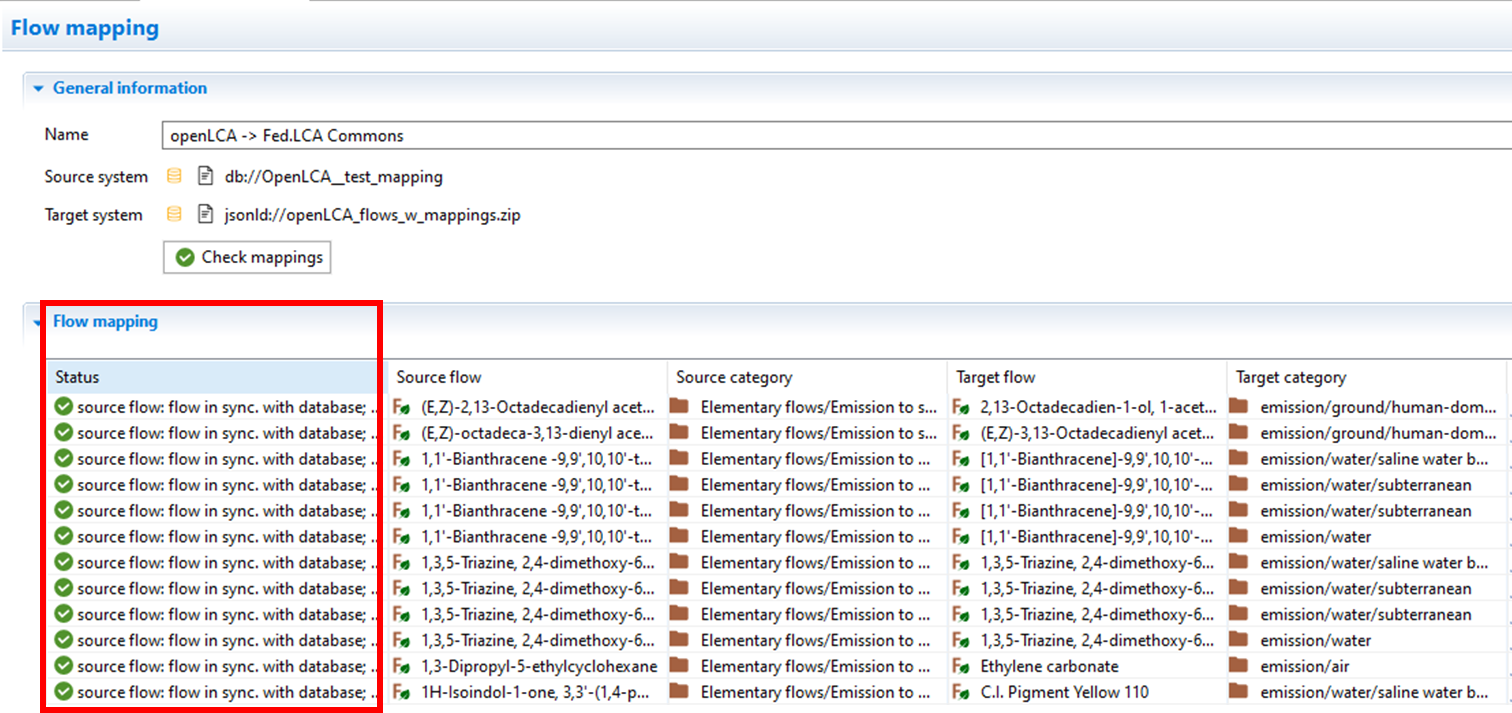 |
If a flow already exists in the database, you will also see a message indicating a flow mapping is not necessary.
To apply the mapping select Flow mapping, Apply on database.
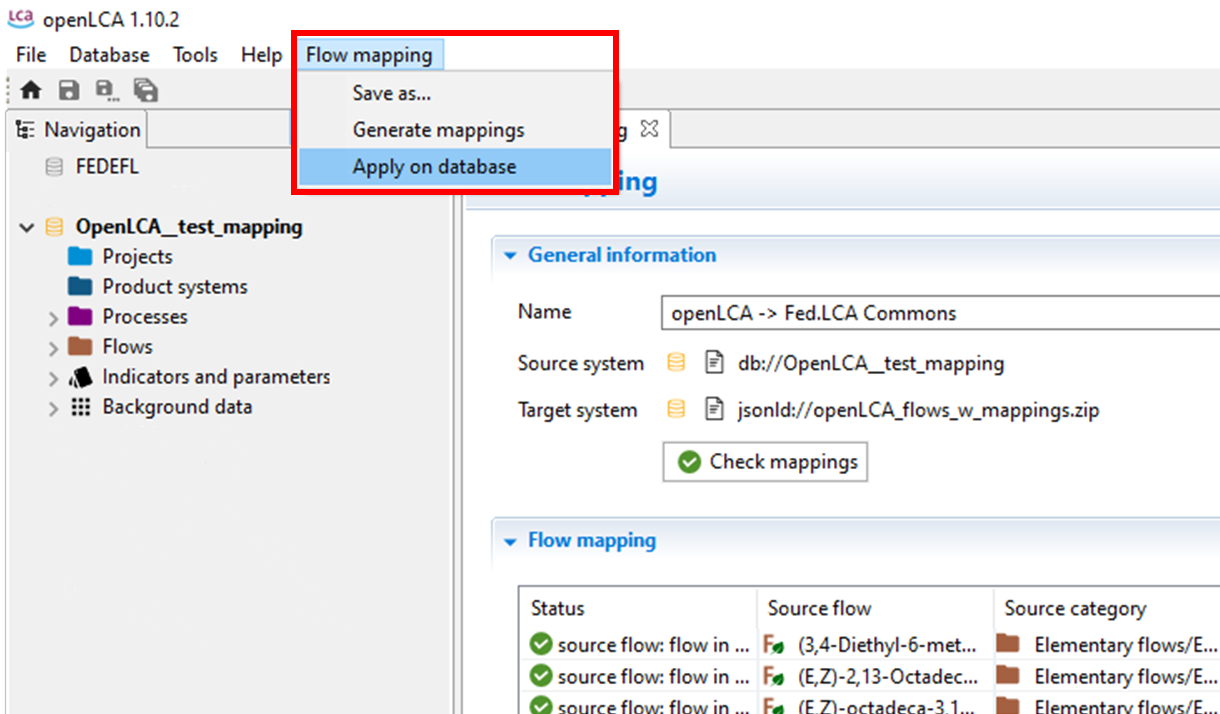 |
You can replace flows in processes, LCIA methods, and flows all in one step by checking the appropriate boxes. Select Delete replaced and unused flows to remove the new obsolete flows.
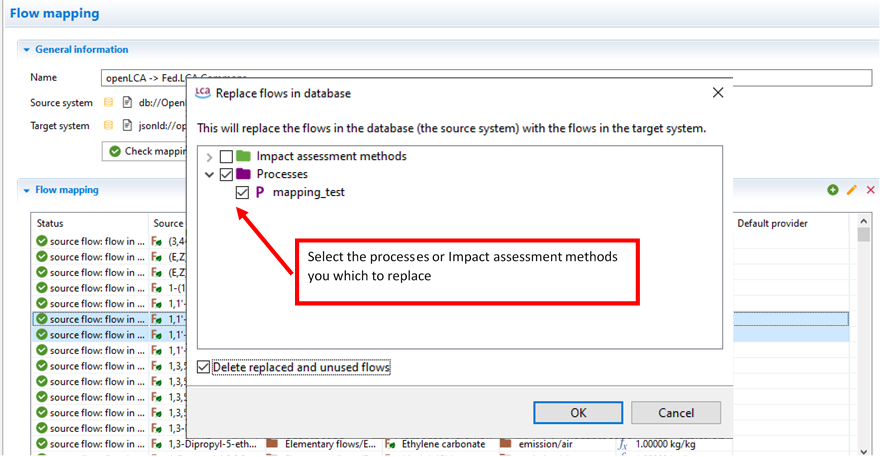 |
 |
Once the mapping is complete, the Flow mapping status will update. If you selected Delete replaced and unused flows then a successful mapping will show that the target mapping was applied to the source flow and removed.
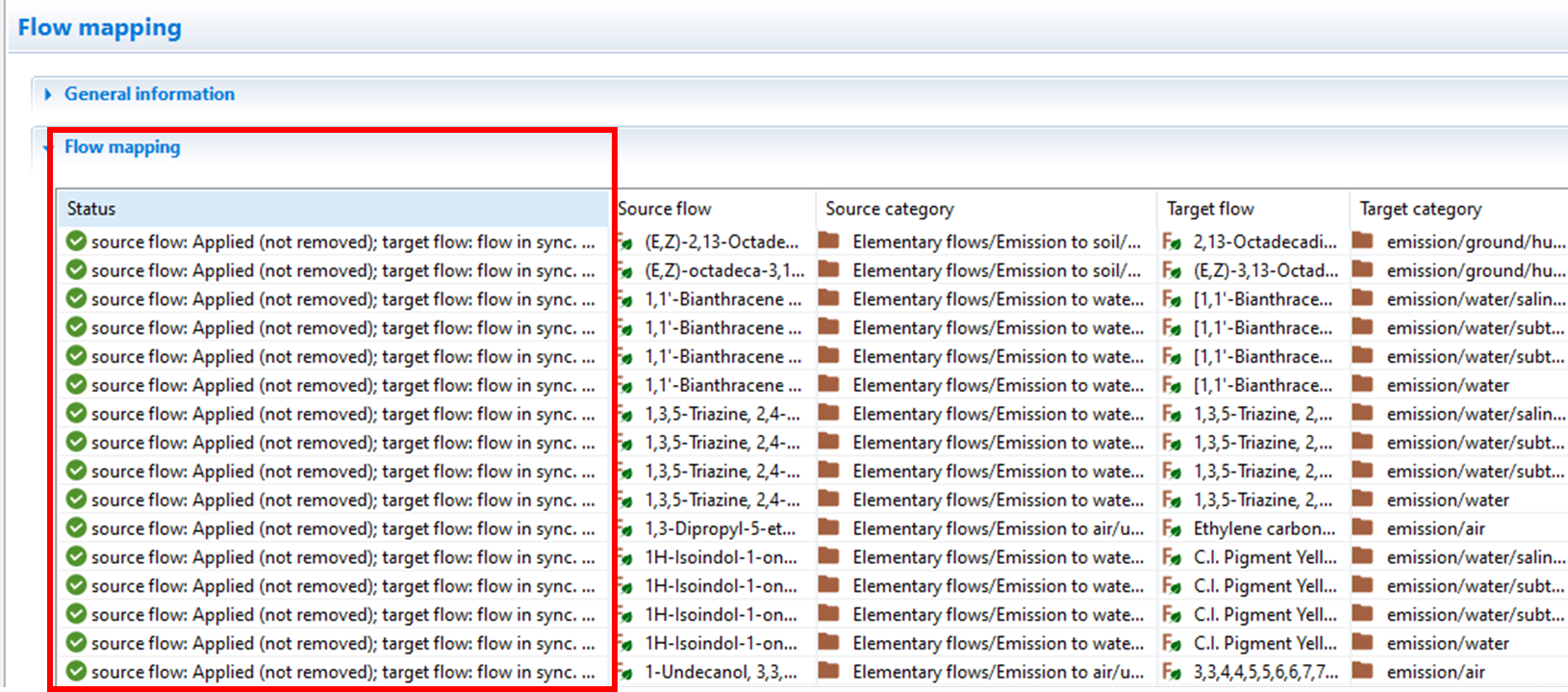 |
Users need to close and reopen a database to make sure that the flow mapping has been applied. Users should confirm that the mappings look correct in their processes and/or LCIA methods (see below for modifications to example process from step 2).
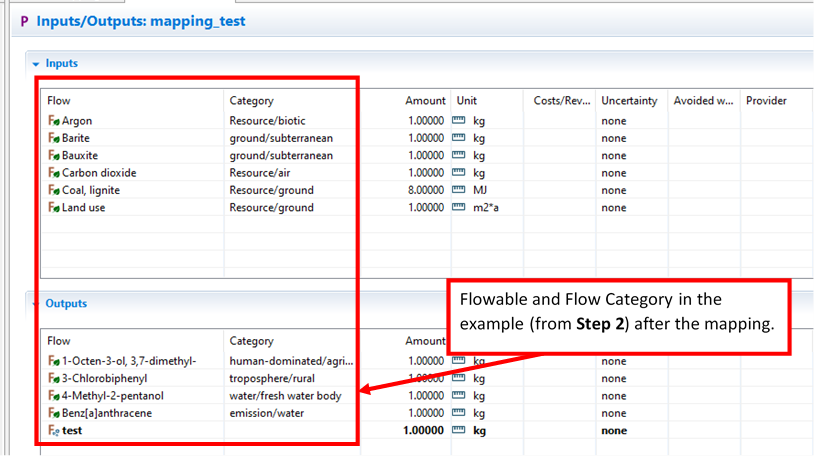 |